Grouped GEMM
最近瞅了一眼 grouped gemm 的代码,发现和我理解的 grouped gemm 有很大差异(我上篇博客中有大概介绍 grouped gemm 的原理)。这里 grouped gemm 的实现就是一个简单的 for 循环,然后调用 cublas 的 gemm 函数。
void CublasGroupedGemm(torch::Tensor a,
torch::Tensor b,
torch::Tensor c,
torch::Tensor batch_sizes,
bool trans_b) {
int64_t bs = batch_sizes.size(0), k = a.size(1);
int64_t n = trans_b ? b.size(1) : b.size(2);
int64_t b_rows = b.size(1), b_cols = b.size(2);
c10::BFloat16* a_ptr = a.data_ptr<c10::BFloat16>();
c10::BFloat16* b_ptr = b.data_ptr<c10::BFloat16>();
c10::BFloat16* c_ptr = c.data_ptr<c10::BFloat16>();
for (int i = 0; i < bs; ++i) {
int64_t m = batch_sizes.data_ptr<int64_t>()[i];
CublasGemm(a_ptr, m, k, /*trans_a=*/false,
b_ptr, b_rows, b_cols, trans_b,
c_ptr, m, n);
a_ptr += m * k;
b_ptr += b_rows * b_cols;
c_ptr += m * n;
}
}
这个在逻辑上和下面的 PyTorch 实现是等价的:
def sequential_gemm(input, weight, batch_sizes):
n = input.shape[0]
out_features = weight.shape[-1]
output = torch.zeros(
n, out_features, dtype=input.dtype, device=input.device
)
cumsum_batch_sizes = torch.cumsum(batch_sizes, dim=0)
# Insert zero at the beginning for offset index's convenience
zero_tensor = torch.zeros(1, dtype=torch.long, device=cumsum_batch_sizes.device)
cumsum_batch_sizes = torch.cat((zero_tensor, cumsum_batch_sizes))
for i in range(weight.shape[0]):
start = cumsum_batch_sizes[i]
end = cumsum_batch_sizes[i + 1]
input_for_this_batch = input[start:end]
out = torch.matmul(input_for_this_batch, weight[i])
output[start:end] = out
return output
我们可以对这两个实现进行 benchmark:
from grouped_gemm import ops
import triton
import torch
import triton.testing
@triton.testing.perf_report(
triton.testing.Benchmark(
x_names=['num_groups'],
x_vals=[2**i for i in range(3, 8)],
line_arg='provider',
line_vals=['sequential', 'grouped'],
line_names=["Sequential GEMM", "Grouped GEMM"],
styles=[('green', '-'), ('blue', '-')],
ylabel="runtime(ms)",
plot_name="sequential-vs-grouped-gemm-performance",
args={},
))
def benchmark(num_groups, provider):
num_groups = num_groups
n = 24576
hidden_size = 1024
a = torch.randn(n, hidden_size).view(-1, hidden_size)
b = torch.randn(num_groups, hidden_size, hidden_size)
dist = torch.rand(num_groups, )
dist /= dist.sum()
batch_sizes = (dist * n).to(torch.long)
error = n - batch_sizes.sum()
batch_sizes[-1] += error
assert batch_sizes.sum() == n
a = a.to(torch.bfloat16).cuda()
b = b.to(torch.bfloat16).cuda()
quantiles = [0.5, 0.2, 0.8]
if provider == 'sequential':
ms, min_ms, max_ms = triton.testing.do_bench(lambda: sequential_gemm(a, b, batch_sizes), quantiles=quantiles)
if provider == 'grouped':
ms, min_ms, max_ms = triton.testing.do_bench(lambda: ops.gmm(a, b, batch_sizes), quantiles=quantiles)
return ms, max_ms, min_ms
benchmark.run(show_plots=True, print_data=True)
得到的结果如下:
sequential-vs-grouped-gemm-performance:
num_groups Sequential GEMM Grouped GEMM
0 8.0 0.241248 0.151296
1 16.0 0.464256 0.229712
2 32.0 0.914784 0.367968
3 64.0 1.717008 0.613440
4 128.0 3.228896 1.117088
可以看到,即使这两个实现在逻辑上是等价的,PyTorch 底层也是调用的 cublas 的 gemm 函数,grouped gemm 的性能要比 sequential gemm 的性能好很多。
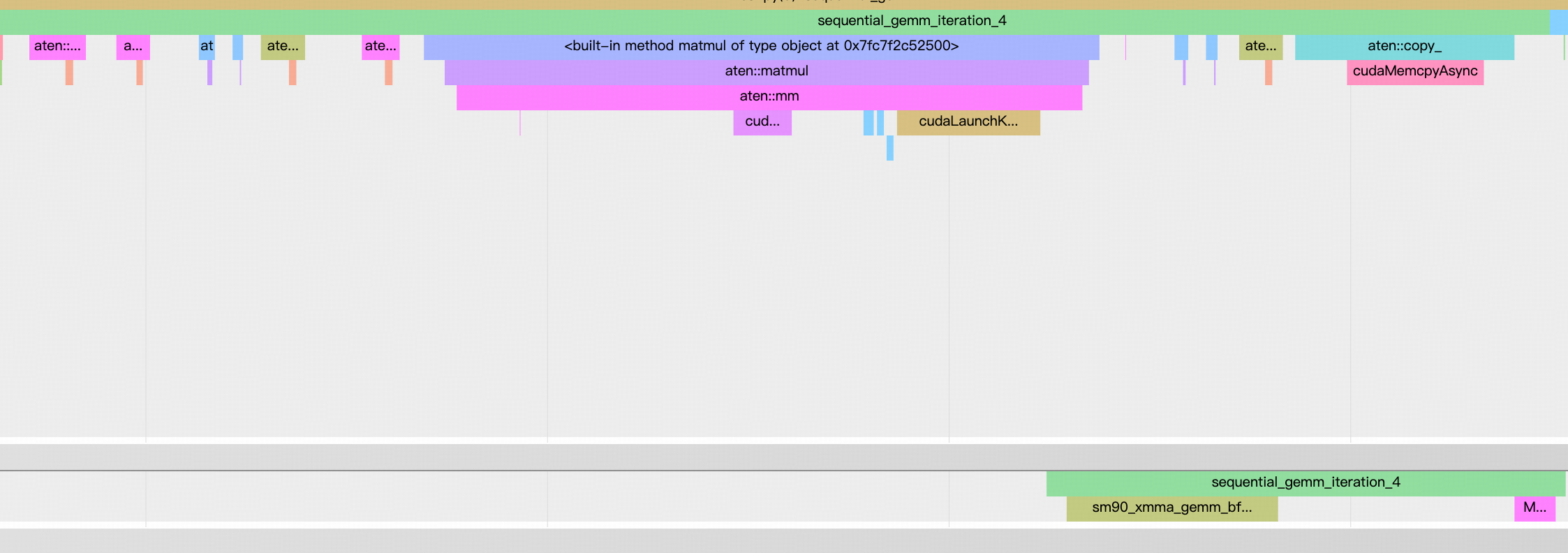 NSight Systems profile of sequential GEMM implementation
NSight Systems profile of sequential GEMM implementation
 NSight Systems profile of grouped GEMM implementation
NSight Systems profile of grouped GEMM implementation
通过 profile 可以看到,grouped gemm 的主要耗时在 kernel launch 以及 gemm 的计算,而 sequential gemm 会有很多额外的 overhead,包括几个 select,slice 操作,以及最后的 memory copy。另外,aten::matmul 相比直接调用 cublas 的 gemm 函数,pytorch 有更多层的封装,层层函数调用带来了额外的 overhead。
另外一个实现是 fanshiqing/grouped_gemm,它在 tgale96/grouped_gemm 的基础上,使用 multi stream 做了优化,benchmark 结果如下:
num_groups Sequential GEMM Grouped GEMM
0 8.0 0.227760 0.145312
1 16.0 0.480816 0.183040
2 32.0 0.982000 0.280992
3 64.0 1.731872 0.467136
4 128.0 3.198544 0.803168
可以看到,使用 multi stream 优化后,性能有明显提升。
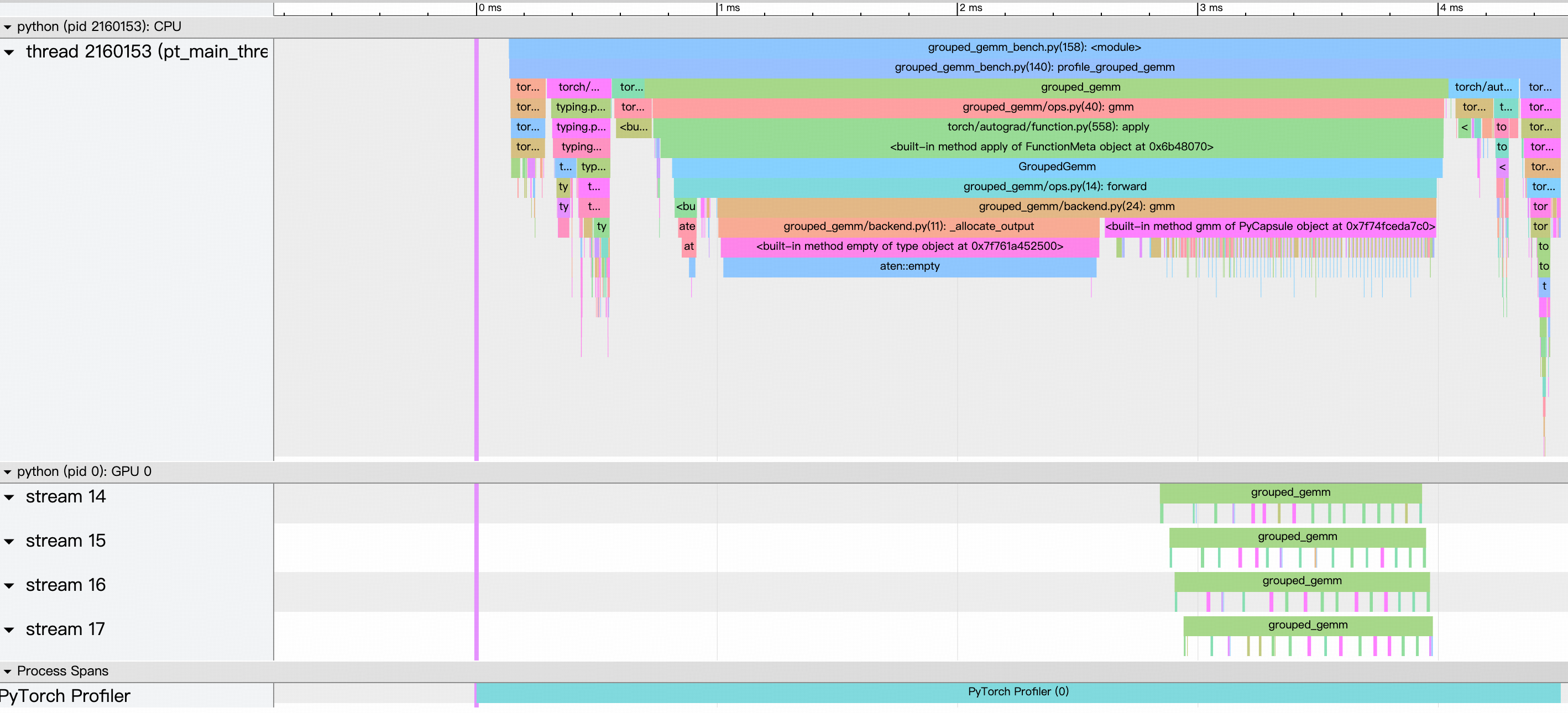 (这里使用了 4 个 stream)
(这里使用了 4 个 stream)
这里的场景是非常适合使用 multi stream 的,因为每个 gemm 都是独立的,由于 gemm 的大小又不一样,每个 gemm 的 workload 不一样,single stream 很容易有一些 GPU compute units 是空闲的。multi stream 可以增大 GPU compute units 的利用率,空闲的 compute units 可以计算其他 stream 中的 gemm。参考下面这张图
