Finetune MoE with LoRA
Finetune MoE with LoRA
用 LoRA 训练 MoE 非常的慢,在 H 卡上 gpu 利用率不到 20%,profile 后发现主要是因为 experts 的计算太慢了。每一层有 64 个 expert,每个 expert 都是一个 mlp,包含一个 gate linear layer、up linear layer 和 down linear layer。
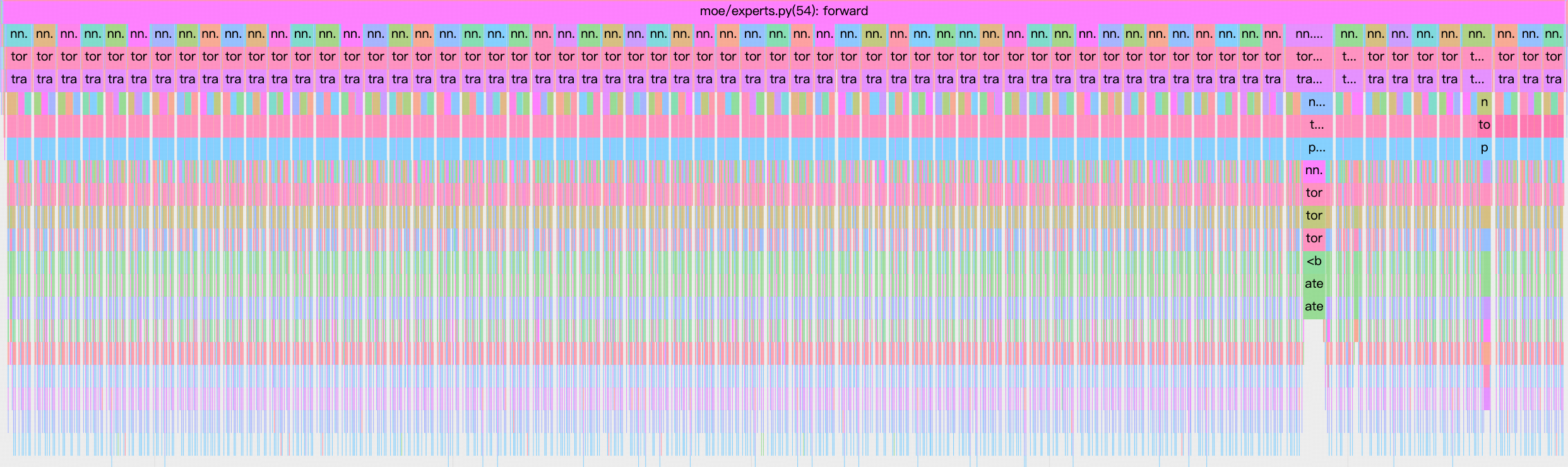
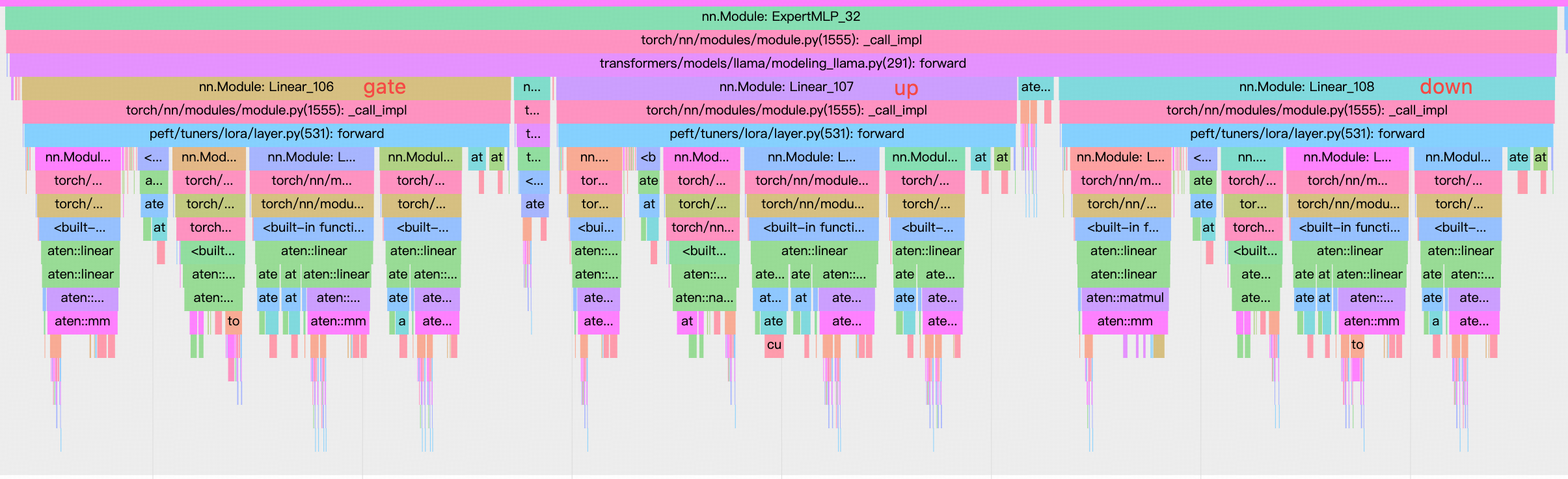
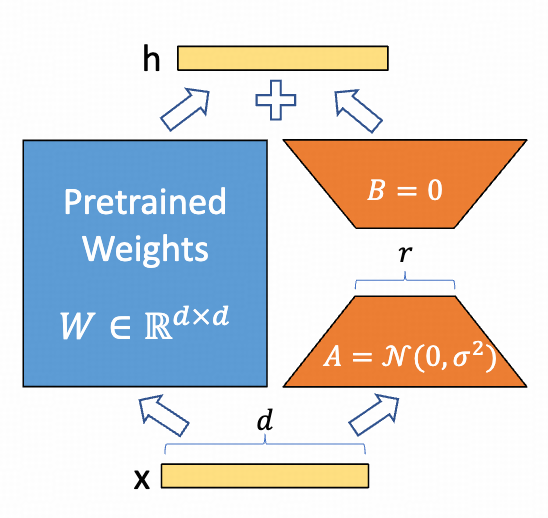
对于每一个 linear layer,LoRA 会再注入两个小 linear layer,如下图。比如原本的是 nn.Linear(1024, 1024),rank 为 16 的 LoRA 会注入 nn.Linear(1024, 16) 和 nn.Linear(16, 1024)。
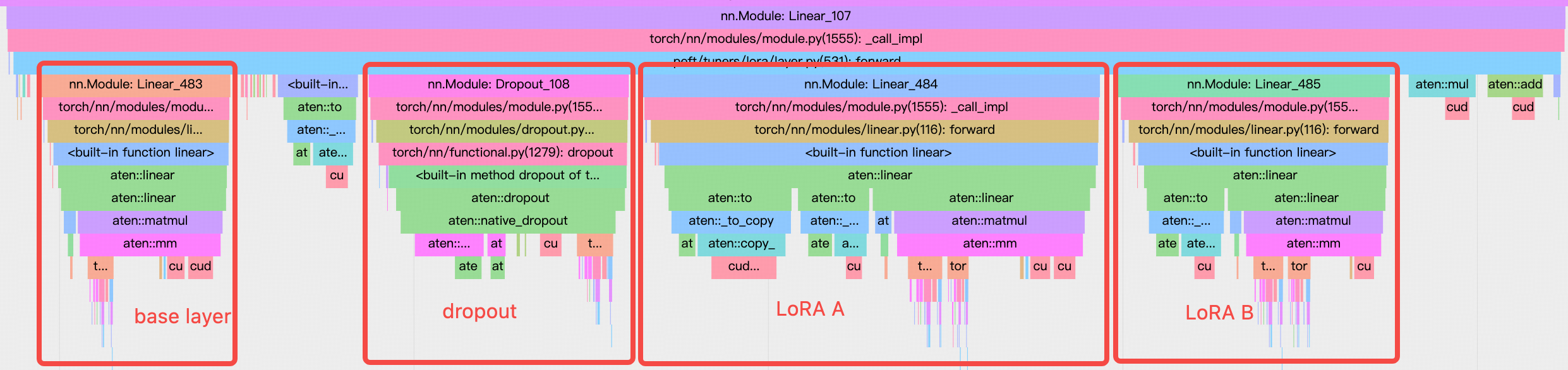
LoRA 的 linear 是一些更小的 linear layer,对于 GPU 来说是 memory bound 的,导致 GPU 的利用率很低。
优化这一块,很容易想到使用 grouped gemm,这也是 MoE 的基操。
Grouped GEMM
当前 experts 是一个 SequentialMLP,假设有 64 个 expert,for 循环这些 expert,且分配给每个 expert 的 token 数不一样, 使得 expert 接收的输入 shape 不一样
class SequentialMLP(nn.Module):
def __init__(self, config):
super().__init__()
self.config = config
self.experts = nn.ModuleList(
[MLP(config) for _ in range(config.moe_num_experts)]
)
def forward(self, permuted_tokens, tokens_per_expert):
output = torch.zeros_like(permuted_tokens)
cumsum_num_tokens = torch.cumsum(tokens_per_expert, dim=0)
# Insert zero at the begining for offset index's convenience
zero_tensor = torch.zeros(1, dtype=torch.long, device=cumsum_num_tokens.device)
cumsum_num_tokens = torch.cat((zero_tensor, cumsum_num_tokens))
for expert_num, expert in enumerate(self.experts):
start = cumsum_num_tokens[expert_num]
end = cumsum_num_tokens[expert_num + 1]
tokens = permuted_tokens[start:end]
out = expert(tokens)
output[start:end] = out
return output
这样做有两个性能问题:一是非常多的 kernel launch,二是每个 expert 接收的输入 shape 不一样,每个 expert 的 workload 不一样,而且使用 LoRA 后这个问题更加严重, 每个 LoRA layer 都是很小的 linear,会导致更多的 SM 空闲。这里的问题就是我们上一篇文章中讨论的 Wave Quantization
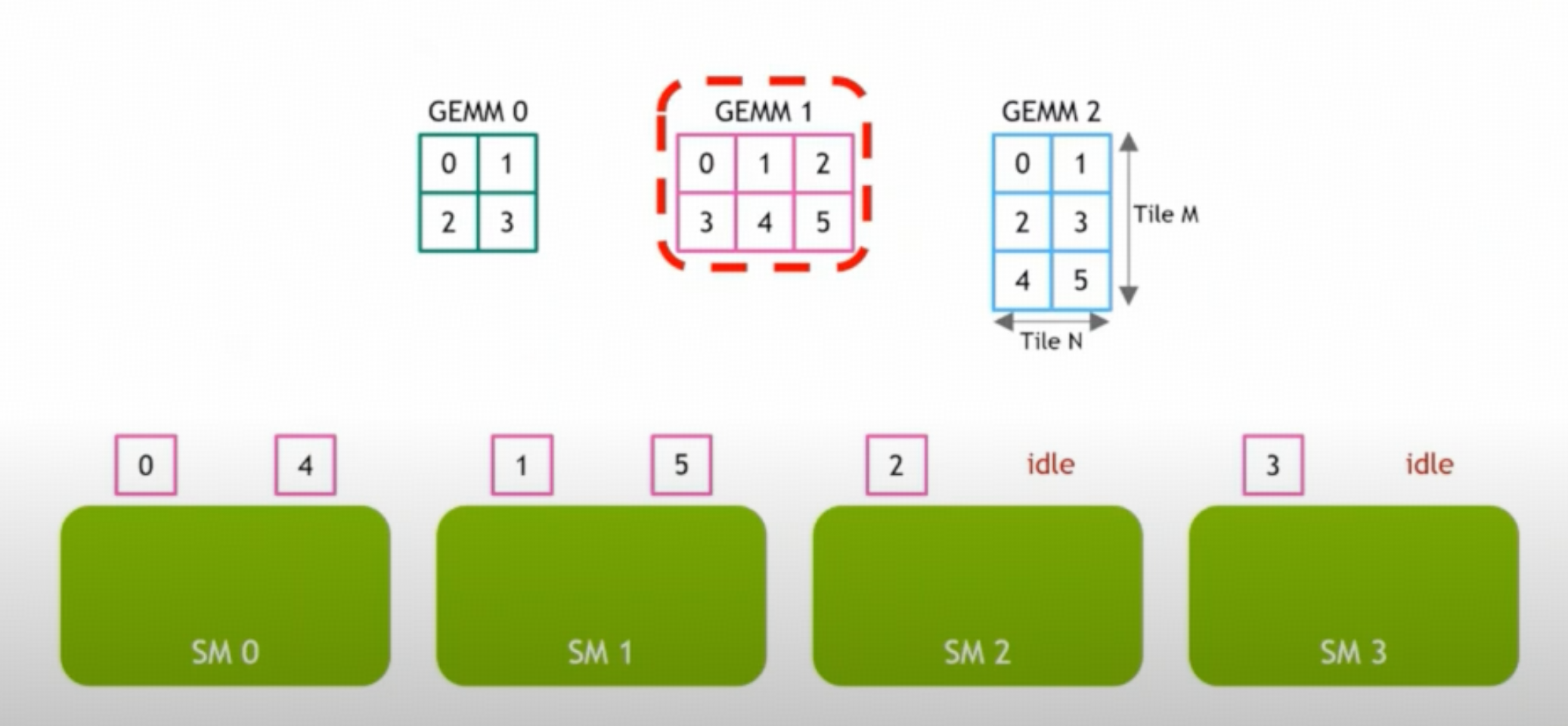
那如果我们所有 expert 的 workload 合到一起,只需一次 kernel launch,work load 也变大了,在 SM 上有更好的 load balance,就可以极大减少 SM 的空闲。
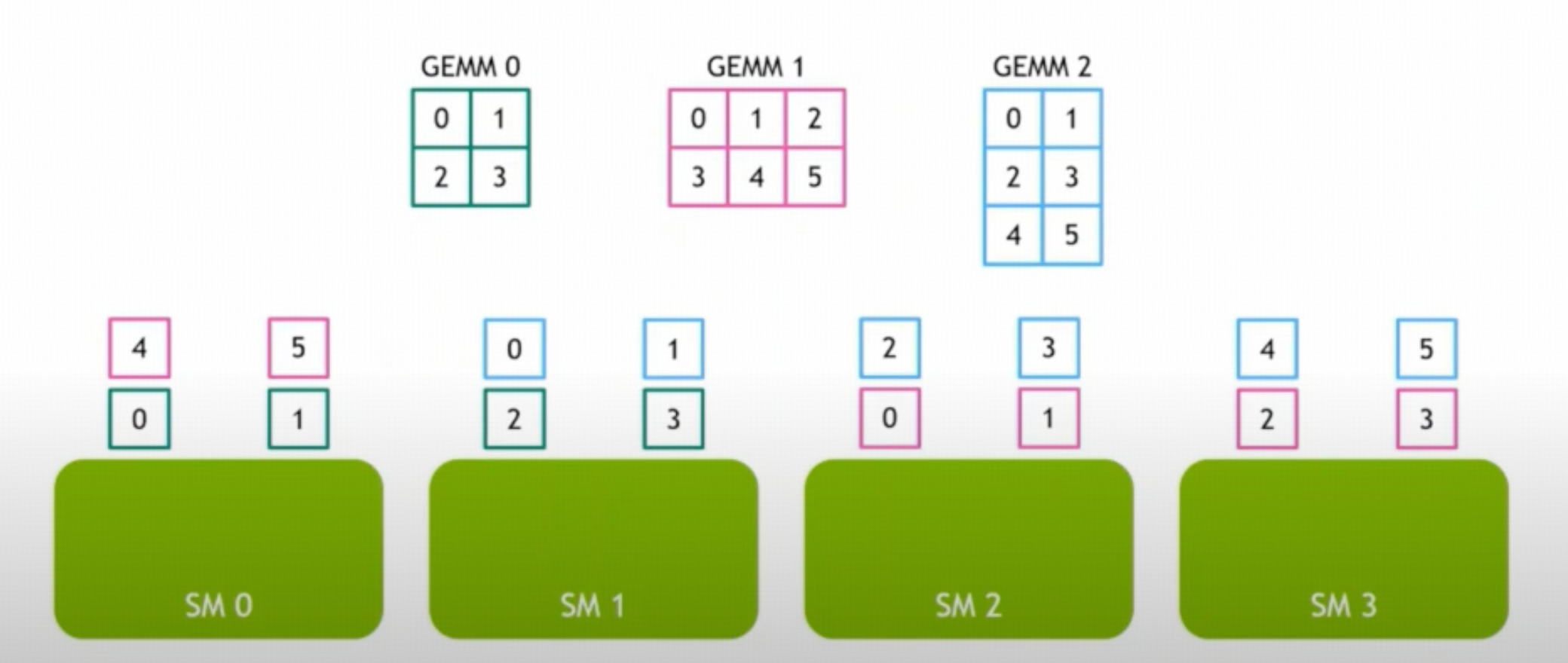
可以参考 Grouped GEMM 的 triton 实现,Grouped GEMM 非常符合 上一篇文章 中 “Don't map threads to data; map data to threads” 的思想,map data to SM!
Finetune with Grouped GEMM
class GroupedMLP(nn.Module):
def __init__(self, config: MoYIConfig):
super().__init__()
self.config = config
fc1_output_size = config.moe_intermediate_size * config.moe_num_experts
if config.hidden_act == "silu":
fc1_output_size *= 2
fc2_input_size = config.moe_intermediate_size * config.moe_num_experts
self.weight1 = nn.Parameter(torch.empty(config.hidden_size, fc1_output_size))
self.weight2 = nn.Parameter(torch.empty(fc2_input_size, config.hidden_size))
def glu(x):
x = torch.chunk(x, 2, dim=-1)
return F.silu(x[0]) * x[1]
self.activation_func = glu
def forward(self, permuted_tokens, tokens_per_expert):
from grouped_gemm import ops
w1 = self.weight1.view(self.config.moe_num_experts, self.config.hidden_size, -1)
w2 = self.weight2.view(self.config.moe_num_experts, -1, self.config.hidden_size)
fc1_output = ops.gmm(permuted_tokens, w1, tokens_per_expert, trans_b=False)
fc1_output = self.activation_func(fc1_output)
fc2_output = ops.gmm(fc1_output, w2, tokens_per_expert, trans_b=False)
return fc2_output
但是使用 Grouped GEMM 的话,PEFT 这个库的 LoRA 不支持 GroupedMLP 这个 moudle。尝试使用 custom models,经过一番尝试,我们对 GroupedMLP 进行了修改
class GroupedGEMM(nn.Module):
def __init__(self, in_features, out_features, groups):
super().__init__()
self.in_features = in_features
self.out_features = out_features
self.groups = groups
self.weight = nn.Parameter(torch.empty(groups, in_features, out_features))
def forward(self, input, tokens_per_expert):
from grouped_gemm import ops
return ops.gmm(input, self.weight, tokens_per_expert)
class GroupedMLP(nn.Module):
def __init__(self, config: MoYIConfig) -> None:
super().__init__()
self.config = config
self.fc1 = GroupedGEMM(
config.hidden_size, config.moe_intermediate_size * 2, config.moe_num_experts
)
self.fc2 = GroupedGEMM(
config.moe_intermediate_size, config.hidden_size, config.moe_num_experts
)
def glu(x):
x = torch.chunk(x, 2, dim=-1)
return F.silu(x[0]) * x[1]
self.activation_func = glu
def forward(self, permuted_tokens, tokens_per_expert):
fc1_output = self.fc1(permuted_tokens, tokens_per_expert)
fc1_output = self.activation_func(fc1_output)
fc2_output = self.fc2(fc1_output, tokens_per_expert)
return fc2_output
定义了一个 GroupedGEMM,这个 module 和 nn.Linear 的接口相似,下面就可以仿照 lora.layer.Linear 去定义 GroupedGEMM 的 LoRA 了。