笔记:How To Write A CUDA Program: The Ninja Edition
How To Write A CUDA Program: The Ninja Edition 是 GTC 2024 的一个 talk。收获很多,记录一下,值得反复观看。
Wave Quantization
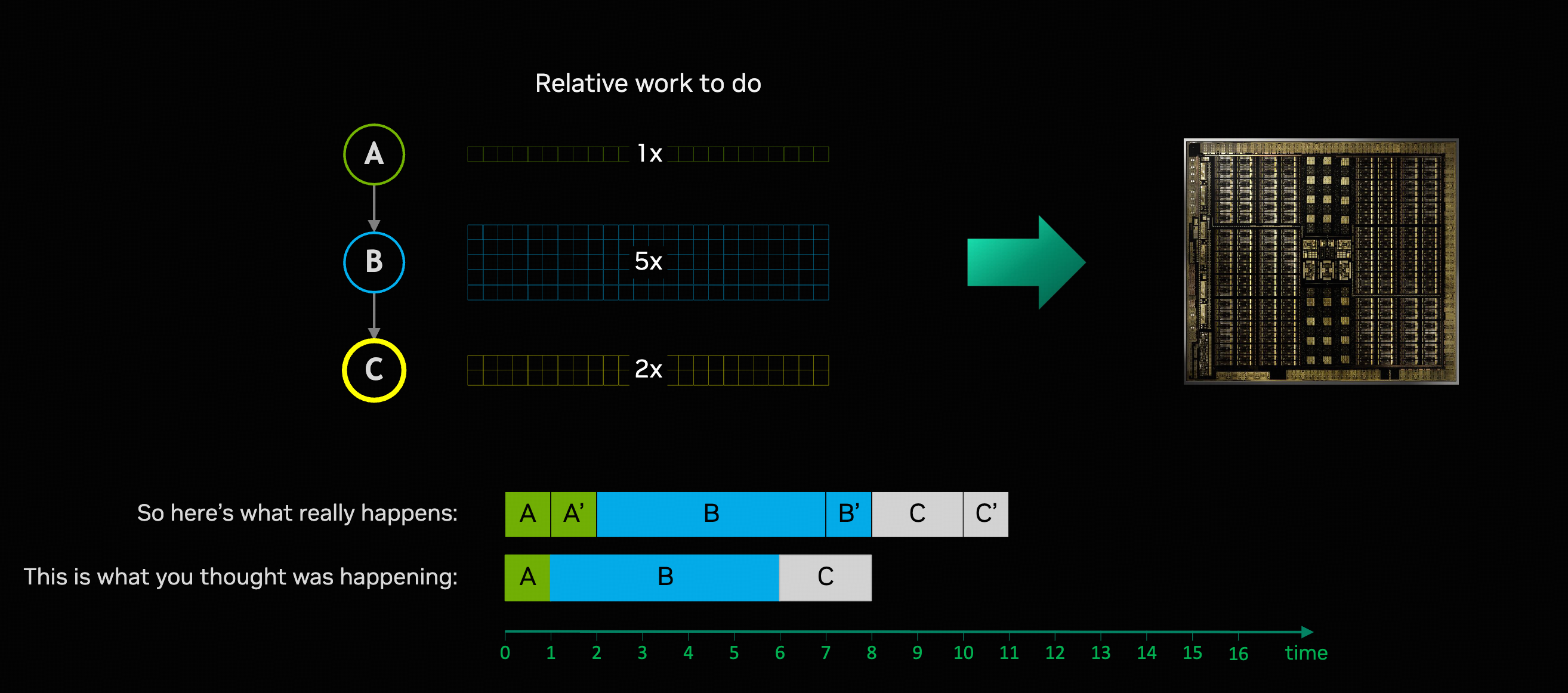
当 thread block 的数量不是 SM 数量的整数倍时,在执行剩余的 thread block 时,一些 SM 会空闲。

对于 task A -> B -> C,每一个阶段都需要一个 extra partial wave。
Don't map threads to data; map data to threads.
这句话应该怎么理解呢?

在上面的例子中,图片大小是 1024x1024,将图片划分为一些 block,你想着划分为 16x16 挺好,每个 block 有 64x64 个像素,然后给每个 block 分配一些 thread 来处理,这就是 map threads to data。H100 有 132 个 SM,这样设计的话,需要两个 wave 才能处理完所有 block。
Map data to threads 的思路是,先考虑 SM 的数量,根据 SM 的数量设计 block 的划分,尽量不让 SM 空闲。
这里可能和 occupancy 容易混淆,occupancy 是指分配给一个 SM 的 warp 数与其支持的最大 warp 数的比例
但是有些情况没办法做到 single-wave 或者 integer-wave:
- 一些算法需要特定大小的 tile
- 必须考虑不同型号的 GPU(比如 RTX-3090/80/70/60)
- 由于使用非 constant 的 tile size 而增加代码复杂度
- 不同 block load balance 的问题,可能不会比增加一个 extra partial wave 好多少
Task Parallelism
在执行 A 的 extra partial wave 时,有很多 SM 空闲,B 是依赖 A 的结果的,所以 B 这时没法利用这些空闲的 SM。但是如果现在有另一个和 A 不相关的的任务,可以让这些 SM 去执行这个任务,这就是 task parallelism。

这样做整体的吞吐量会提高,但是单一任务的 latency 并不一定会降低,比如图中的 Task 1: A -> B -> C 的 latency 比之前变高了。
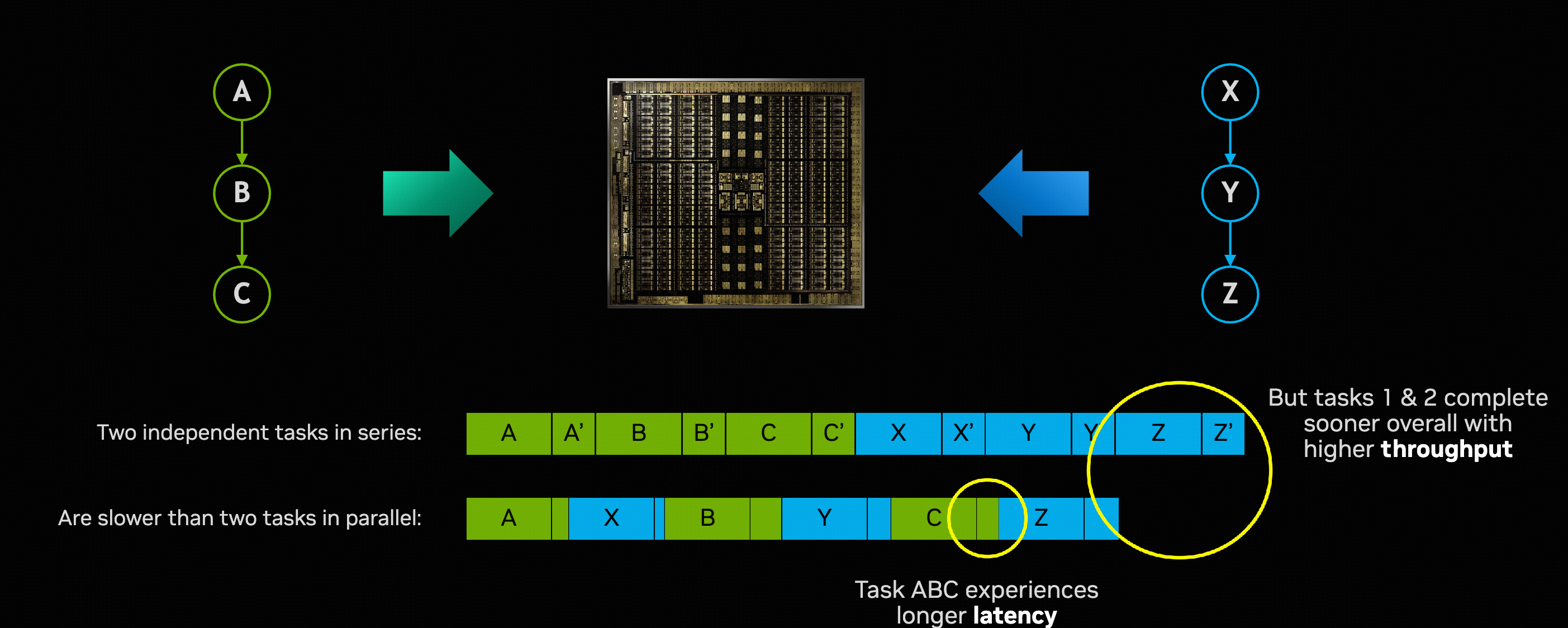
Task parallelism 有一个很大的问题,就是 thrashing cache。同时执行的 task 变多,每个 task 能分配到的 cache 就会变少,需要更频繁的和 global memory 交互。如果 task 是一个 memory-bound 的任务,task parallelism 也不一定会提高整体的吞吐。
Keep Data in Cache
L2 cache == shared memory
对于 task A -> B -> C,有如下过程:
- A 从 global memory 读取数据到 shared memory
- A 计算
- A 将结果写回 global memory
- B 从 global memory 读取数据到 shared memory
- B 计算
- B 将结果写回 global memory
- C 从 global memory 读取数据到 shared memory
- C 计算
- C 将结果写回 global memory
设想一下如果 task 足够小,小到中间计算结果完全可以放在 shared memory 中,那么就不需要这么多次 global memory 的读写了。执行 A -> B -> C 的过程就变成了:
- A 从 global memory 读取数据到 shared memory
- A 计算
- B 从 shared memory 读取 A 的结果
- B 计算
- C 从 shared memory 读取 B 的结果
- C 计算
- C 将结果写回 global memory
当然,并不是所有任务都可以这样做,但是如果能找到一种方式将 task 拆分为更小的 task,使得这些小 task 可以完全放在 shared memory 中,让这些小 task 串行执行。

这其实就是 flash attention 的优化思路。