Triton Puzzles: 从 softmax 到 flash attention
受 Triton Puzzles 启发,把 flash attention 的实现过程拆分成一系列的 puzzle,逐步用 triton 去实现,以一个更平滑的学习曲线来学习 triton 和 flash attention。但是
- 本文不会介绍 flash attention 的原理,阅读本文最好是对 flash attention 有一定了解,但不是必须的。
- 本文不会介绍 triton 的一些基本用法,阅读本文至少得看懂 triton 官方的第一个 tutorial:Vector Addition
Attention 的计算公式如下
flash attention 的核心思路是通过分块计算,将中间计算 fuse 在一起,避免来回读写中间结果(, softmax),减少访问 HBM 的次数,提高计算效率。
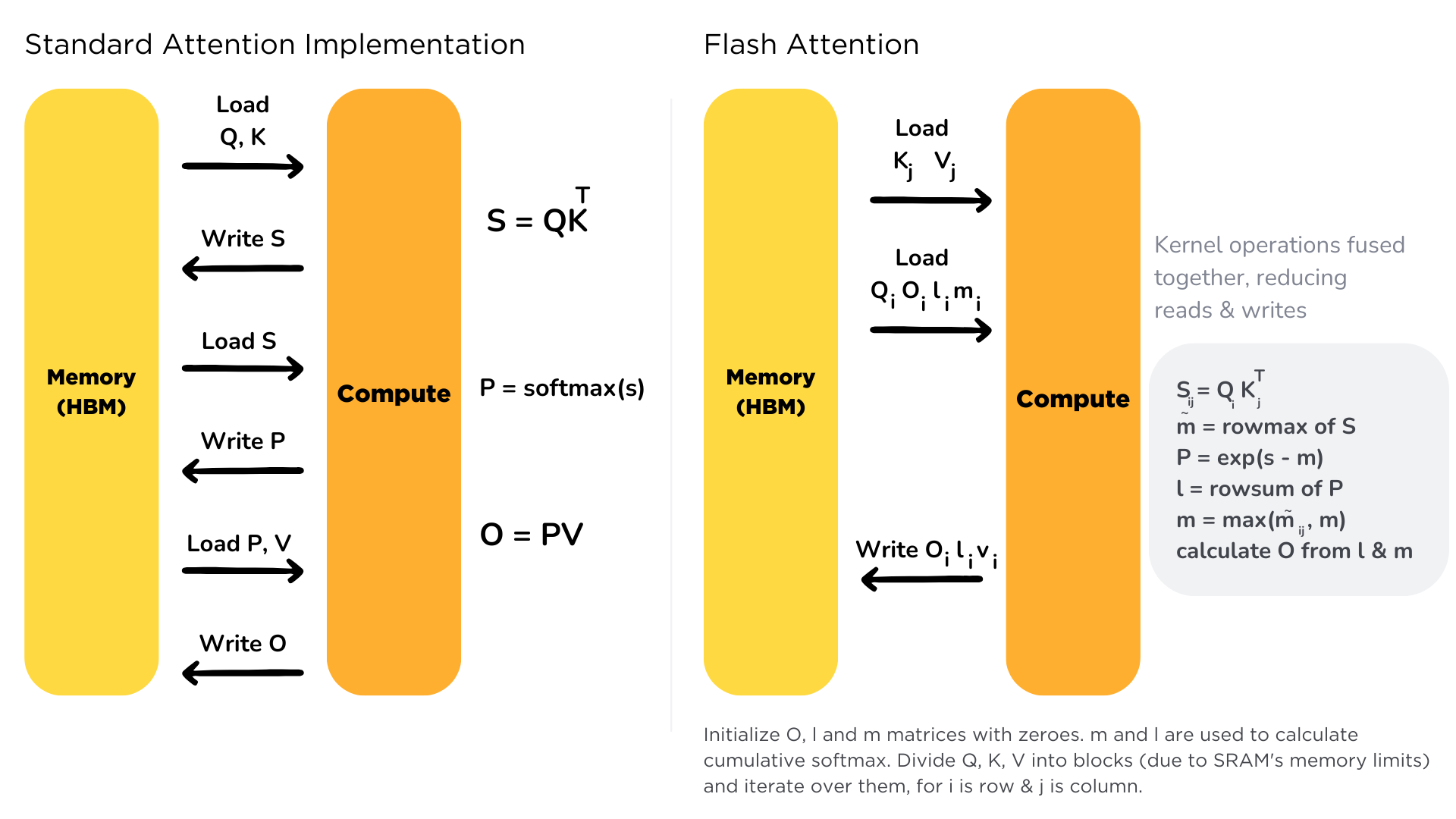
我们的最终目标是用 triton 实现 flash attention v2 的 forward,即下面这个伪代码
Puzzle 1:softmax
对一个 2D 矩阵,计算 softmax
我们先用 pytorch 实现
def softmax(x):
x_max = x.max(dim=-1, keepdim=True)[0]
x = x - x_max
x_exp = x.exp()
x_exp_sum = x_exp.sum(dim=-1, keepdim=True)
return x_exp / x_exp_sum
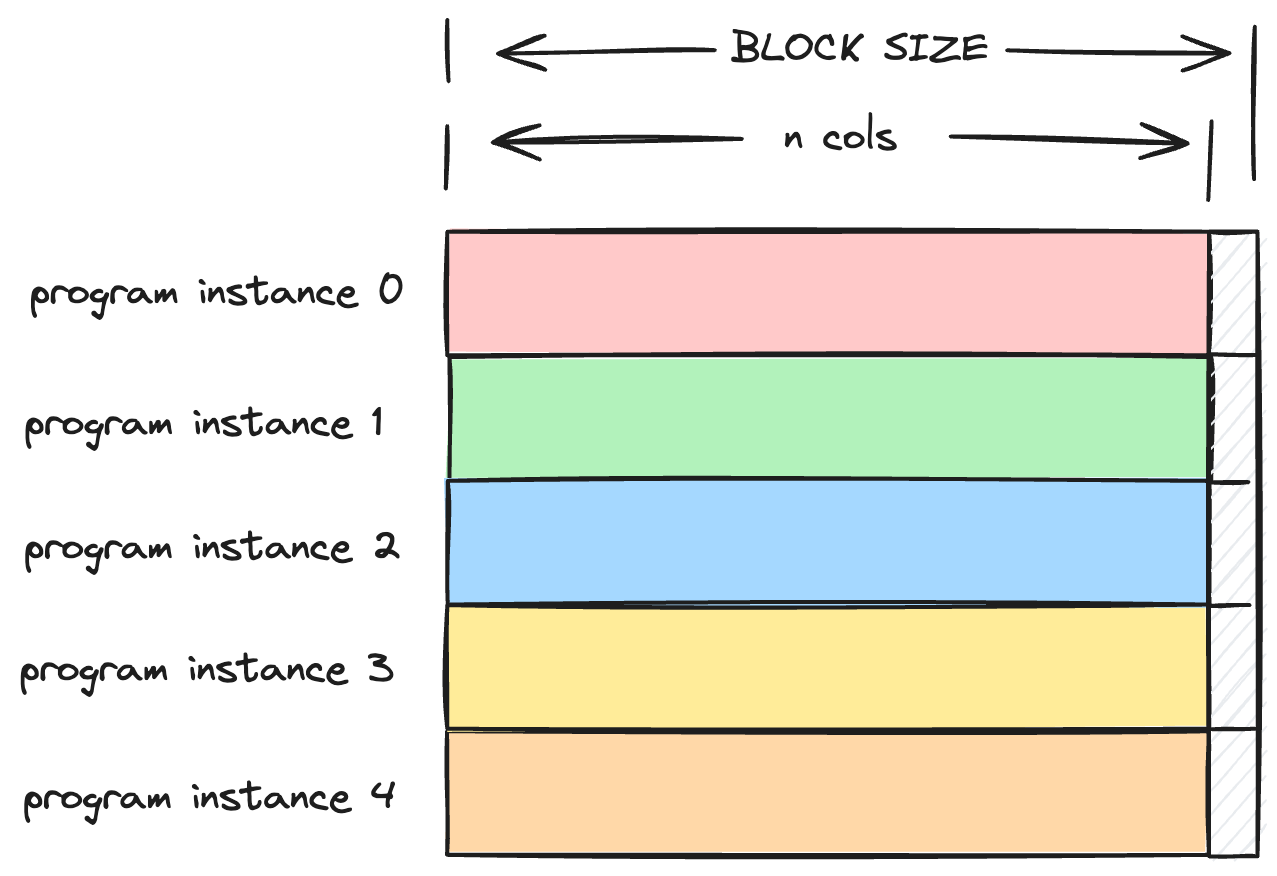
每个 program instance 计算一行的 softmax
@triton.jit
def softmax_kernel(x_ptr, output_ptr, row_stride, n_cols, BLOCK_SIZE: tl.constexpr):
pid = tl.program_id(0)
# BLOCK_SIZE is bigger than the number of columns
col_range = tl.arange(0, BLOCK_SIZE)
col_mask = col_range < n_cols
x = tl.load(x_ptr + pid * row_stride + col_range, mask=col_mask)
x_max = tl.max(x, axis=-1)
x = x - x_max
x_exp = tl.exp(x)
x_exp_sum = tl.sum(x_exp, axis=-1)
tl.store(output_ptr + pid * row_stride + col_range, x_exp / x_exp_sum, mask=col_mask)
def triton_softmax(x):
n_rows, n_cols = x.shape
BLOCK_SIZE = triton.next_power_of_2(n_cols)
output = torch.empty_like(x)
softmax_kernel[(n_rows,)](
x,
output,
x.stride(0),
n_cols,
BLOCK_SIZE,
)
return output
这个实现非常简单,可以是看做对 pytorch 代码的一对一翻译

Puzzle 2: 分块算 softmax
上面我们一次 load 了一整行的数据,如果我们一次只 load 一行的一部分数据呢?
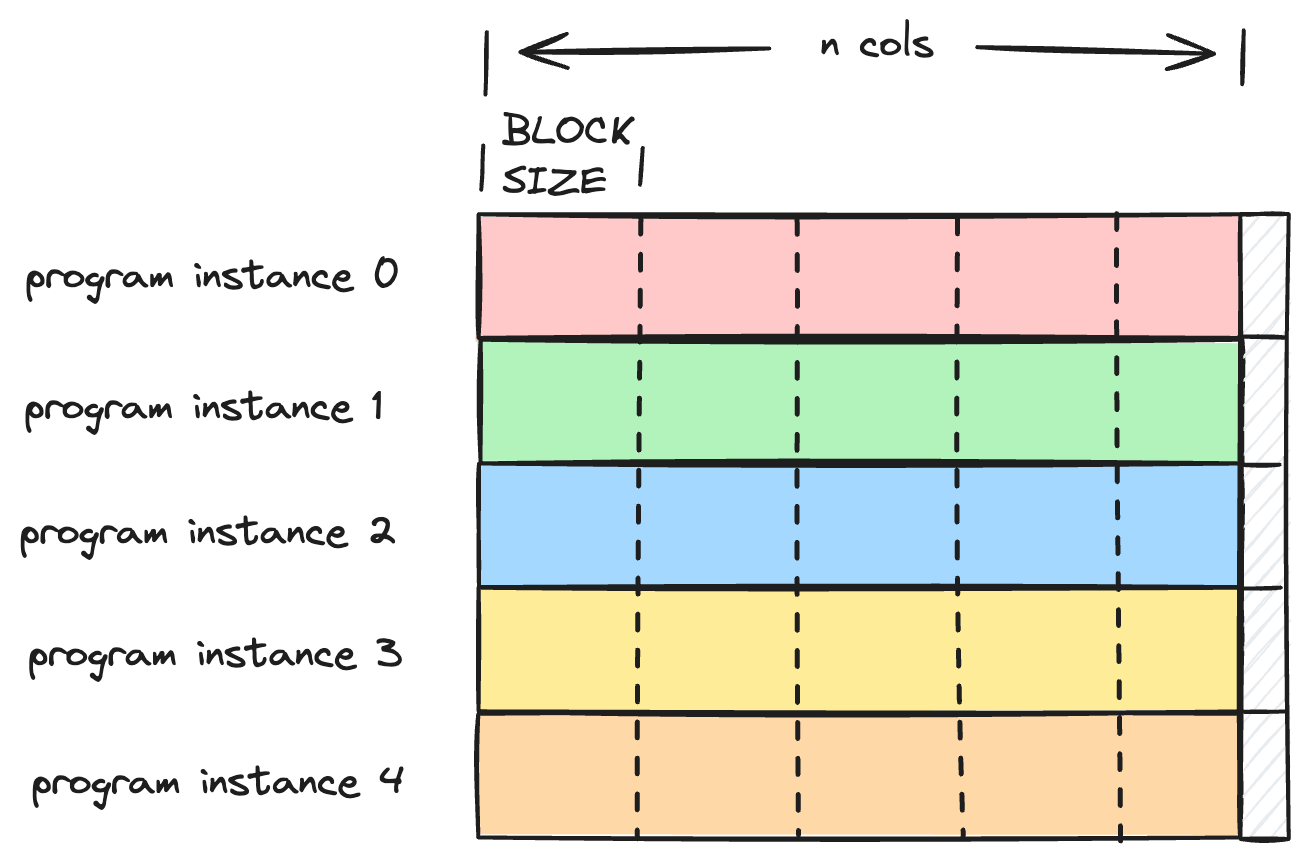
是不是简单加个 for loop 就行了?
@triton.jit
def softmax_kernel(x_ptr, output_ptr, row_stride, n_cols, BLOCK_SIZE: tl.constexpr):
pid = tl.program_id(0)
for offset in range(0, n_cols, BLOCK_SIZE):
col_range = tl.arange(0, BLOCK_SIZE)
col_mask = col_range + offset < n_cols
x = tl.load(x_ptr + pid * row_stride + col_range + offset, mask=col_mask)
x_max = tl.max(x, axis=-1)
x = x - x_max
x_exp = tl.exp(x)
x_exp_sum = tl.sum(x_exp, axis=-1)
tl.store(output_ptr + pid * row_stride + col_range + offset, x_exp / x_exp_sum, mask=col_mask)
稍加思考,我们就会发现这个实现是有问题的,因为我们计算 x_max 和 x_exp_sum 的时候只考虑了当前的 block,而期望得到的是整行的 x_max 和 x_exp_sum。
我们再用两个 for loop,一个计算 x_max,一个计算 x_exp_sum,然后再计算 softmax
@triton.jit
def softmax_kernel_v2(x_ptr, output_ptr, row_stride, n_cols, BLOCK_SIZE: tl.constexpr):
pid = tl.program_id(0)
x_max = -float('inf')
for offset in range(0, n_cols, BLOCK_SIZE):
col_range = tl.arange(0, BLOCK_SIZE)
col_mask = col_range + offset < n_cols
x = tl.load(x_ptr + pid * row_stride + col_range + offset, mask=col_mask, other=-float('inf'))
x_max = tl.maximum(x_max, tl.max(x, axis=-1))
x_exp_sum = 0.0
for offset in range(0, n_cols, BLOCK_SIZE):
col_range = tl.arange(0, BLOCK_SIZE)
col_mask = col_range + offset < n_cols
x = tl.load(x_ptr + pid * row_stride + col_range + offset, mask=col_mask, other=-float('inf'))
x_exp_sum = x_exp_sum + tl.sum(tl.exp(x - x_max), axis=-1)
for offset in range(0, n_cols, BLOCK_SIZE):
col_range = tl.arange(0, BLOCK_SIZE)
col_mask = col_range + offset < n_cols
x = tl.load(x_ptr + pid * row_stride + col_range + offset, mask=col_mask)
x_exp = tl.exp(x - x_max)
tl.store(output_ptr + pid * row_stride + col_range + offset, x_exp / x_exp_sum, mask=col_mask)
def triton_softmax_v2(x):
n_rows, n_cols = x.shape
output = torch.empty_like(x)
BLOCK_SIZE = 256
softmax_kernel_v2[(n_rows,)](
x,
output,
x.stride(0),
n_cols,
BLOCK_SIZE
)
return output
Puzzle 3: online softmax
一个更聪明的做法是,我们可以在一次 for loop 中计算 x_max 和 x_exp_sum,这样我们就可以减少一次 for loop。参考 paper Online normalizer calculation for softmax

我们可以使用归纳法证明这个算法的正确性。
当 时(即向量只有一个元素), 是输入向量中的最大值,,符合softmax函数的定义。
假设对于 ,上述方法正确地计算了 和 。
然后对于 ,我们需要证明算法也能准确计算 和 。
这表明更新后的 正确地表示了前 个输入元素的最大值。
根据归纳假设,可以将 展开为 ,通过替换和简化,我们可以得到:
这表明更新后的 正确地计算了前 个元素,相对于新的最大值 的归一化因子。
对应的 triton 代码如下:
@triton.jit
def softmax_kernel_v3(x_ptr, output_ptr, row_stride, n_cols, BLOCK_SIZE: tl.constexpr):
pid = tl.program_id(0)
x_max = -float('inf')
x_exp_sum = 0.0
for offset in range(0, n_cols, BLOCK_SIZE):
col_range = tl.arange(0, BLOCK_SIZE)
col_mask = col_range + offset < n_cols
x = tl.load(x_ptr + pid * row_stride + col_range + offset, mask=col_mask, other=-float('inf'))
x_max_new = tl.maximum(x_max, tl.max(x, axis=-1))
x_exp_sum = x_exp_sum * tl.exp(x_max - x_max_new) + tl.sum(tl.exp(x - x_max_new), axis=-1)
x_max = x_max_new
for offset in range(0, n_cols, BLOCK_SIZE):
col_range = tl.arange(0, BLOCK_SIZE)
col_mask = col_range + offset < n_cols
x = tl.load(x_ptr + pid * row_stride + col_range + offset, mask=col_mask)
x_exp = tl.exp(x - x_max)
tl.store(output_ptr + pid * row_stride + col_range + offset, x_exp / x_exp_sum, mask=col_mask)
def triton_softmax_v3(x):
n_rows, n_cols = x.shape
output = torch.empty_like(x)
BLOCK_SIZE = 256
softmax_kernel_v3[(n_rows,)](
x,
output,
x.stride(0),
n_cols,
BLOCK_SIZE
)
return output
Puzzle 4: 更通用的分块策略
前面我们都是按行分块,更通用的分块策略是按行和列都分块
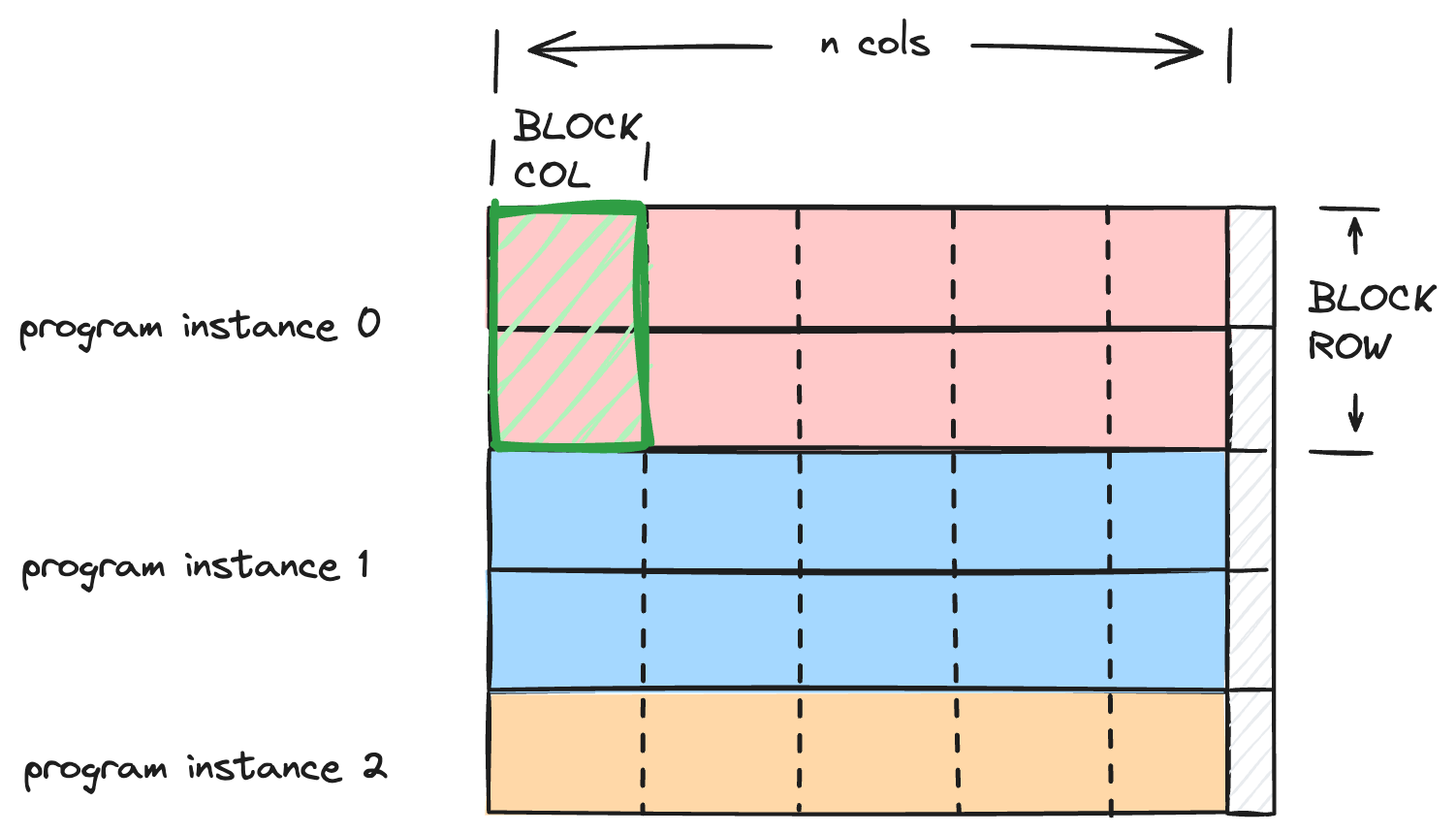
@triton.jit
def softmax_kernel_v4(x_ptr, output_ptr, row_stride, n_rows, n_cols, BLOCK_ROW: tl.constexpr, BLOCK_COL: tl.constexpr):
pid = tl.program_id(0)
x_max = tl.full((BLOCK_ROW, ), -float('inf'), dtype=tl.float32)
x_exp_sum = tl.full((BLOCK_ROW, ), 0.0, dtype=tl.float32)
for offset in range(0, n_cols, BLOCK_COL):
row_range = tl.arange(0, BLOCK_ROW) + pid * BLOCK_ROW
col_range = tl.arange(0, BLOCK_COL) + offset
x_mask = (row_range[:, None] < n_rows) & (col_range < n_cols)
x_range = row_range[:, None] * row_stride + col_range
x = tl.load(x_ptr + x_range, mask=x_mask, other=-float('inf'))
x_max_new = tl.maximum(x_max, tl.max(x, axis=-1))
x_exp_sum = tl.exp(x_max - x_max_new) * x_exp_sum + tl.sum(tl.exp(x - x_max_new[:, None]), axis=-1)
x_max = x_max_new
for offset in range(0, n_cols, BLOCK_COL):
row_range = tl.arange(0, BLOCK_ROW) + pid * BLOCK_ROW
col_range = tl.arange(0, BLOCK_COL) + offset
x_mask = (row_range[:, None] < n_rows) & (col_range < n_cols)
x_range = row_range[:, None] * row_stride + col_range
x = tl.load(x_ptr + x_range, mask=x_mask)
x_exp = tl.exp(x - x_max[:, None])
tl.store(output_ptr + x_range, x_exp / x_exp_sum[:, None], mask=x_mask)
def triton_softmax_v4(x):
n_rows, n_cols = x.shape
output = torch.empty_like(x)
grid = lambda meta: (triton.cdiv(n_rows, meta['BLOCK_ROW']), )
softmax_kernel_v4[grid](
x,
output,
x.stride(0),
n_rows,
n_cols,
32,
256
)
return output
flash attention 的实现
最后,我们可以按照 flash attention 的伪代码实现 forward

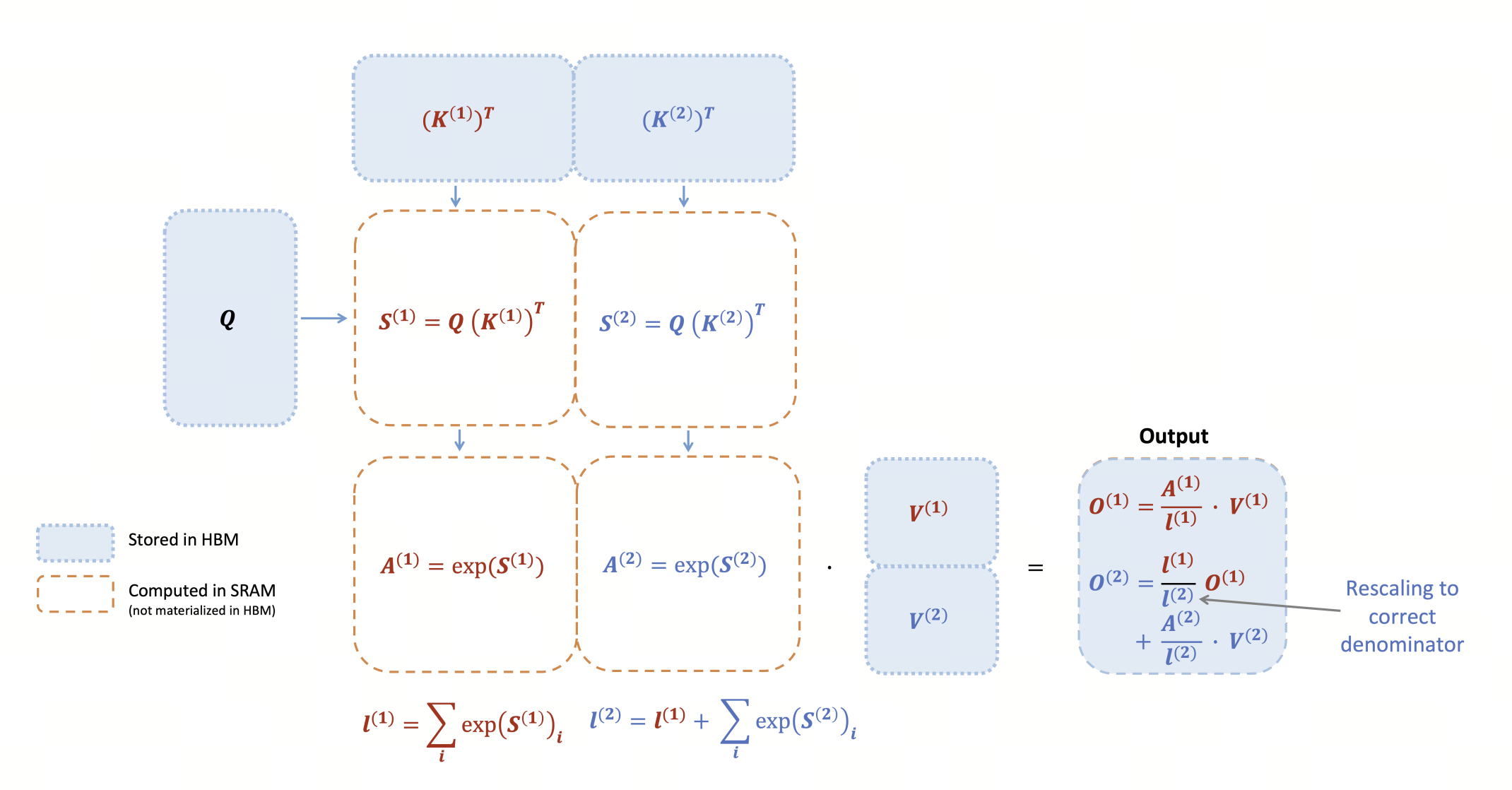
@triton.jit
def flash_attention_kernel(q_ptr, k_ptr, v_ptr, output_ptr, n, d: tl.constexpr, BR: tl.constexpr, BC: tl.constexpr):
pid = tl.program_id(0)
q_row_range = tl.arange(0, BR) + pid * BR
q_range = q_row_range[:, None] * d + tl.arange(0, d)
q_mask = (q_row_range[:, None] < n) & (tl.arange(0, d) < d)
q = tl.load(q_ptr + q_range, mask=q_mask)
o = tl.full((BR, d), 0, dtype=tl.float32)
l = tl.full((BR,), 0, dtype=tl.float32)
m = tl.full((BR,), -float('inf'), dtype=tl.float32)
for j in range(0, n, BC):
kv_row_range = tl.arange(0, BC) + j
kv_range = kv_row_range[:, None] * d + tl.arange(0, d)
kv_mask = (kv_row_range[:, None] < n) & (tl.arange(0, d) < d)
k = tl.load(k_ptr + kv_range, mask=kv_mask, other=0)
v = tl.load(v_ptr + kv_range, mask=kv_mask, other=0)
s = tl.dot(q, tl.trans(k))
s_mask = (q_row_range[:, None] < n) & (kv_row_range < n)
s = tl.where(s_mask, s, -float('inf'))
m_new = tl.maximum(m, tl.max(s, axis=-1))
p = tl.exp(s - m_new[:, None])
l = tl.exp(m - m_new) * l + tl.sum(p, axis=-1)
o = tl.exp(m - m_new)[:, None] * o + tl.dot(p, v)
m = m_new
tl.store(output_ptr + q_range, o / l[:, None], mask=q_mask)
def flash_attention(q, k, v):
n, d = q.shape
BR = 32
BC = 64
output = torch.empty((n, d), device=q.device)
grid = lambda meta: (triton.cdiv(n, BR),)
flash_attention_kernel[grid](
q,
k,
v,
output,
n,
d,
BR,
BC,
)
return output