大模型训练优化——我的问题合集
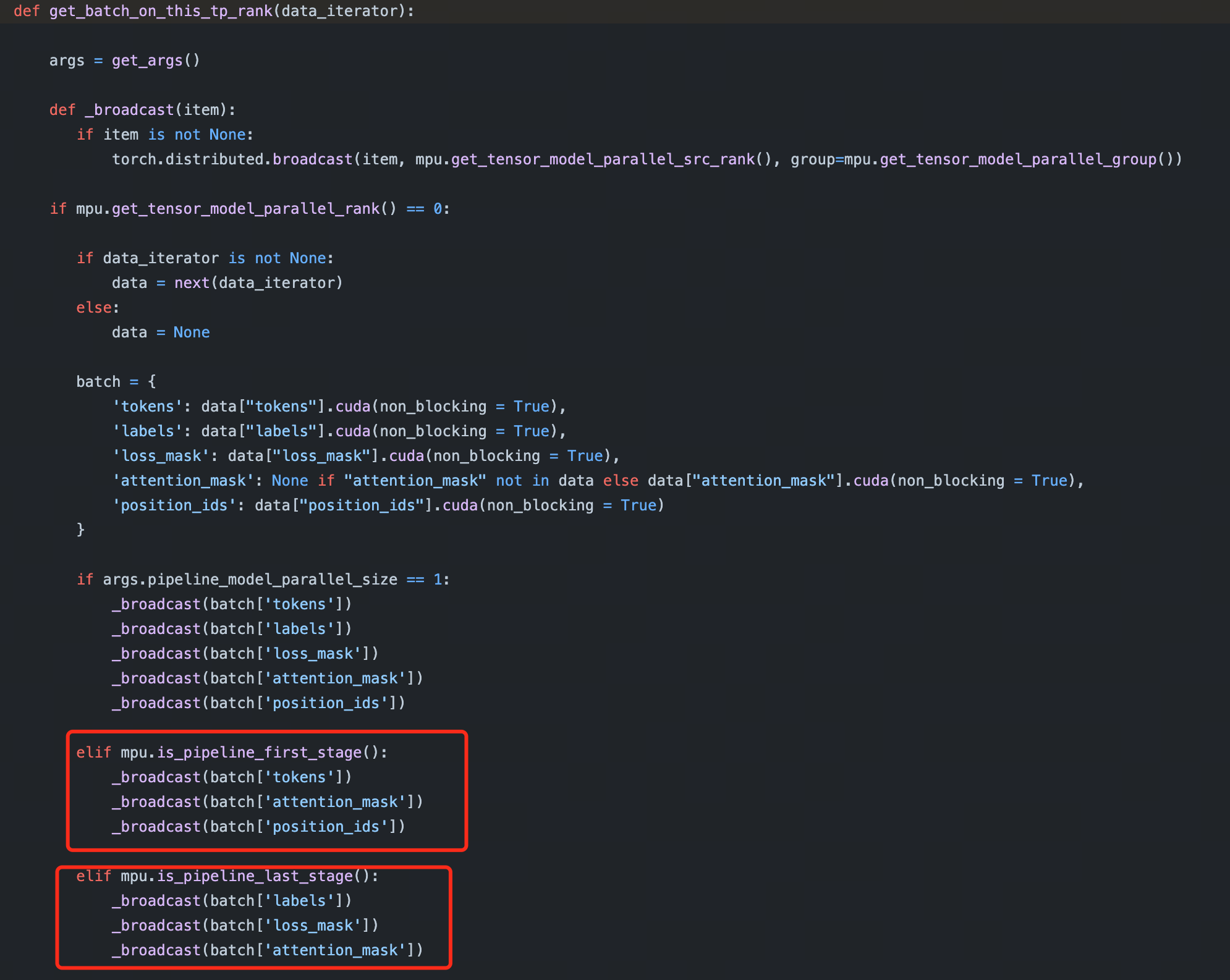
为什么 Megatron-LM 要在 PP 的第一 stage 和最后一个 stage 的 rank 上 build dataset 呢?
看代码可以发现 Megatron-LM 在 build dataset 的时候,会根据 rank 来决定是否 build dataset,如果 PP 是第一个 stage 或者最后一个 stage 的 rank,那么就会 build dataset。
# https://github.com/NVIDIA/Megatron-LM/blob/2196398f5252ead6f036b06d45f7acb89b1308da/pretrain_gpt.py#L168-L169
def is_dataset_built_on_rank():
return (mpu.is_pipeline_first_stage() or mpu.is_pipeline_last_stage()) and mpu.get_tensor_model_parallel_rank() == 0
我的疑问其实是只用在第一个 stage build dataset 不就好了吗?其他 stage 的输入数据都是上一个 stage 的输出,通过网络传输过来的,为什么还要在最后一个 stage build dataset 呢?
这么做的原因是一个 batch 的数据包含 tokens, labels, loss_mask, attention_mask, position_ids,其中 labels, loss_mask 只在计算 loss 的时候用到,而 loss 的计算是在最后一个 stage 进行的,这些数据从第一个 stage 传到最后一个 stage 的过程中,会占用一些带宽,所以在最后一个 stage build dataset 可以减少数据传输的带宽。
Megatron-LM 中 --overlap-grad-reduce 和 --overlap-param-gather 是在做什么?
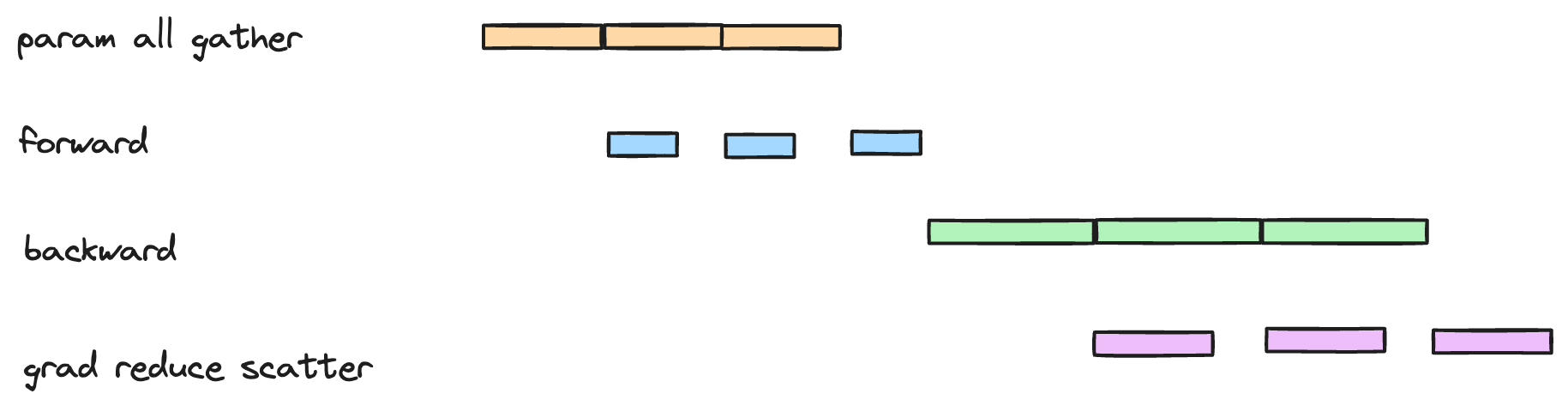
简单来说,这两个参数是想在 DDP 下,做 forward,backward 以及 all reduce 之间的通信与计算的重叠。

核心的思路是不用等到所有的梯度都计算完了再进行 all reduce,而是在计算梯度的同时就开始 all reduce,这样可以减少计算和通信的时间。

比如说模型有 12 个 layer,可以分为 3 组,每组 4 个 layer,那么可以这样做,layer 8-11 backward 结束后,就可以开始这几个 layer 的 all reduce,与此同时 layer 4-7 的 backward 也可以开始。
更进一步,all reduce 可以拆为 reduce scatter 和 all gather,(细节可以参考 手把手推导Ring All-reduce的数学性质) 这样拆的好处是 forward 也可以做重叠。先 all gather 前面一些层的参数,就可以开始 forward,与此同时 all gather 之后的一些层。

整体的流程如下: