LLM.C 中的 CUDA Kernel
Matmul
__global__ void __launch_bounds__(16*16, 2) matmul_forward_kernel4(float* out,
const float* inp, const float* weight, const float* bias,
int C, int OC) {
// out is (B,T,OC). OC is short for "output channels", e.g. OC = 4 * C
// inp is (B,T,C), weight is (OC, C), bias is (OC)
// each thread handles 8x8 elements; each block 128 by 128 elements.
int oc = 8*(blockIdx.y * blockDim.y + threadIdx.y);
// buffers to cache chunks of the input matrices
__shared__ float lhs_s[128][32];
__shared__ float rhs_s[128][32];
// adjust our pointers for the current block
inp += 128 * blockIdx.x * C;
weight += 128 * blockIdx.y * C;
out += 128 * blockIdx.x * OC + 128 * blockIdx.y;
float vals[8][8] = {};
if(bias != NULL) {
for (int i = 0; i < 8; i++) {
for (int j = 0; j < 8; j += 4) {
float4 b = ld_vec(bias + oc + j);
vals[i][j+0] = b.x;
vals[i][j+1] = b.y;
vals[i][j+2] = b.z;
vals[i][j+3] = b.w;
}
}
}
int si_start = 4*(16 * threadIdx.y + threadIdx.x);
for (int so = 0; so < C; so += 32) {
__syncthreads();
int xmod8 = threadIdx.x % 8;
int xby8 = threadIdx.x / 8;
int xo = 4 * xmod8;
for(int y = 2 * threadIdx.y + xby8; y < 128; y += 32) {
st_vec(&lhs_s[y][xo], ld_vec(inp + y * C + so + xo));
st_vec(&rhs_s[y][xo], ld_vec(weight + y * C + so + xo));
}
__syncthreads();
for (int si = si_start; si < si_start + 32; si += 4) {
float4 rhs[8];
for (int u = 0; u < 8; ++u) {
rhs[u] = ld_vec(&rhs_s[u + 8 * threadIdx.y][si % 32]);
}
for (int ii = 0; ii < 8; ++ii) {
float4 lhs = ld_vec(&lhs_s[ii + 8 * threadIdx.x][si % 32]);
for (int ji = 0; ji < 8; ++ji) {
vals[ii][ji] += lhs.x * rhs[ji].x;
vals[ii][ji] += lhs.y * rhs[ji].y;
vals[ii][ji] += lhs.z * rhs[ji].z;
vals[ii][ji] += lhs.w * rhs[ji].w;
}
}
}
}
for (int i = 0; i < 8; ++i) {
for (int j = 0; j < 8; j += 4) {
float4 result;
result.x = vals[i][j + 0];
result.y = vals[i][j + 1];
result.z = vals[i][j + 2];
result.w = vals[i][j + 3];
st_vec(out + (8*threadIdx.x+i) * OC + 8*threadIdx.y + j, result);
}
}
}
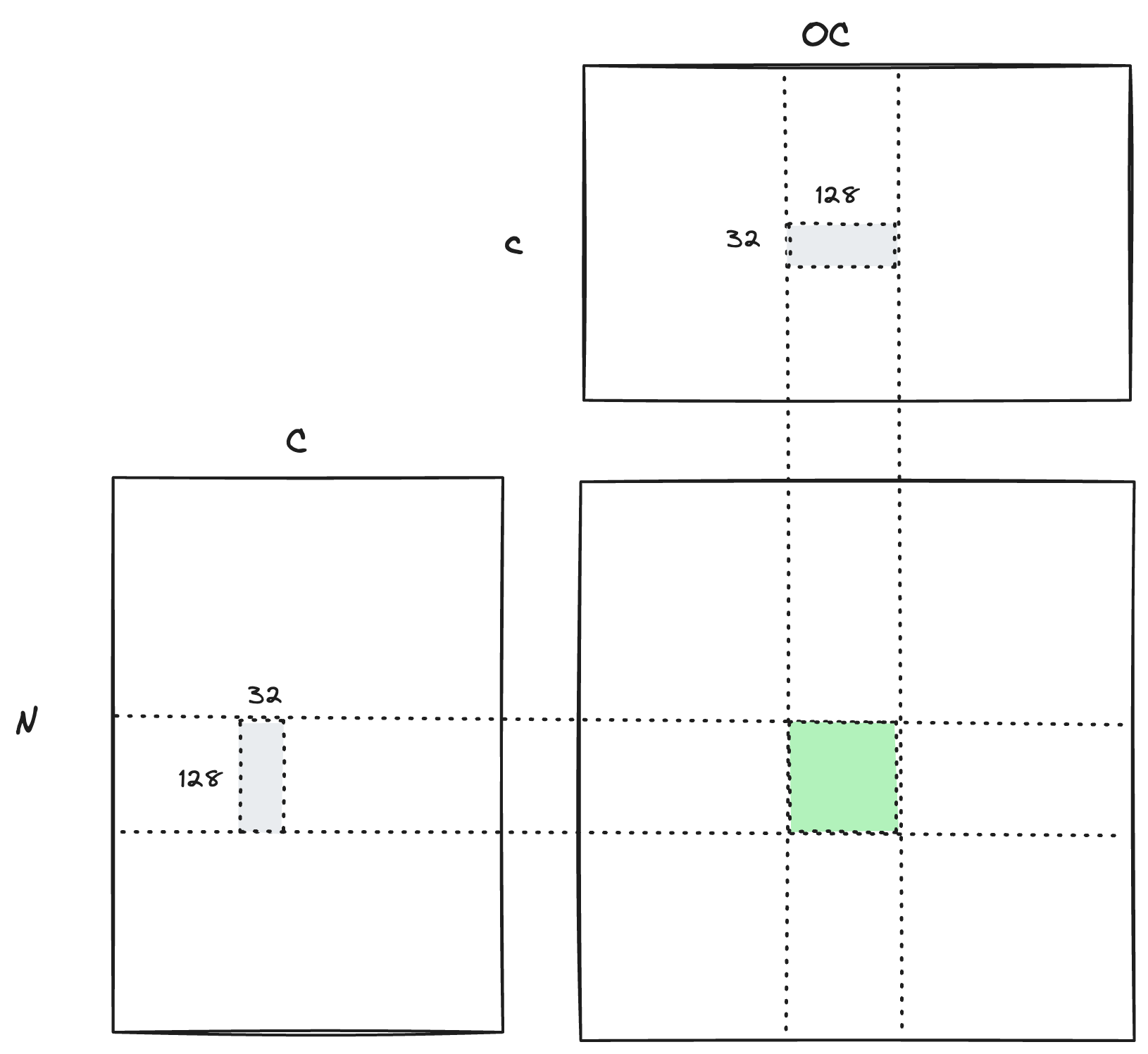
对于 shape 为 [N, C] 和 [C, OC] 的矩阵乘法,每个 thread block 处理 [128, C] 和 [C, 128] 的矩阵乘法。计算 [128, C] * [C, 128] 的时候,每次将两个矩阵的一部分,即 [128, 32] 和 [32, 128] 加载到 shared memory 中,然后计算结果。这对应第一个 for loop
for (int so = 0; so < C; so += 32) {
__syncthreads();
int xmod8 = threadIdx.x % 8;
int xby8 = threadIdx.x / 8;
int xo = 4 * xmod8;
for(int y = 2 * threadIdx.y + xby8; y < 128; y += 32) {
st_vec(&lhs_s[y][xo], ld_vec(inp + y * C + so + xo));
st_vec(&rhs_s[y][xo], ld_vec(weight + y * C + so + xo));
}
__syncthreads();
...
}
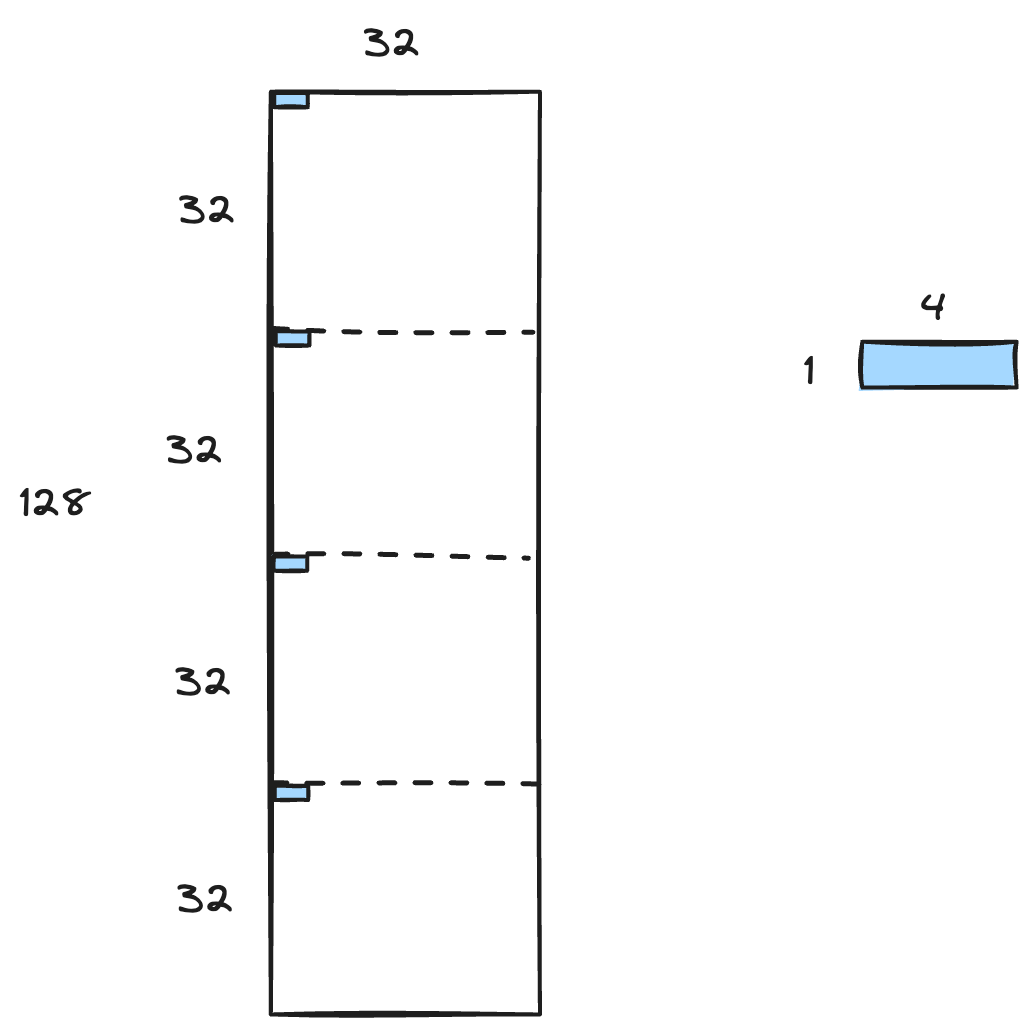
每个 thread block 包含 16 * 16 个 thread,thread block 中的 thread 一起协作把 [128, 32] 的两个矩阵分别加载到 shared memory 中。128 * 32 / (16 * 16) = 16,所以每个 thread 负责加载 16 个元素。threadidx (0, 0) 负责加载的元素如下图所示
这里对应的代码如下
int xmod8 = threadIdx.x % 8;
int xby8 = threadIdx.x / 8;
int xo = 4 * xmod8;
for(int y = 2 * threadIdx.y + xby8; y < 128; y += 32) {
st_vec(&lhs_s[y][xo], ld_vec(inp + y * C + so + xo));
st_vec(&rhs_s[y][xo], ld_vec(weight + y * C + so + xo));
}
其中 st_vec 和 ld_vec 分别 store 和 load 4 个 float
__device__ float4 ld_vec(const float* address) {
return *reinterpret_cast<const float4*>(address);
}
__device__ void st_vec(float* address, float4 val) {
*reinterpret_cast<float4*>(address) = val;
}
一个 thread block 包含 16 * 16 个 thread,每个 thread 负责计算 [8, 32] * [32, 8] 的矩阵乘法。
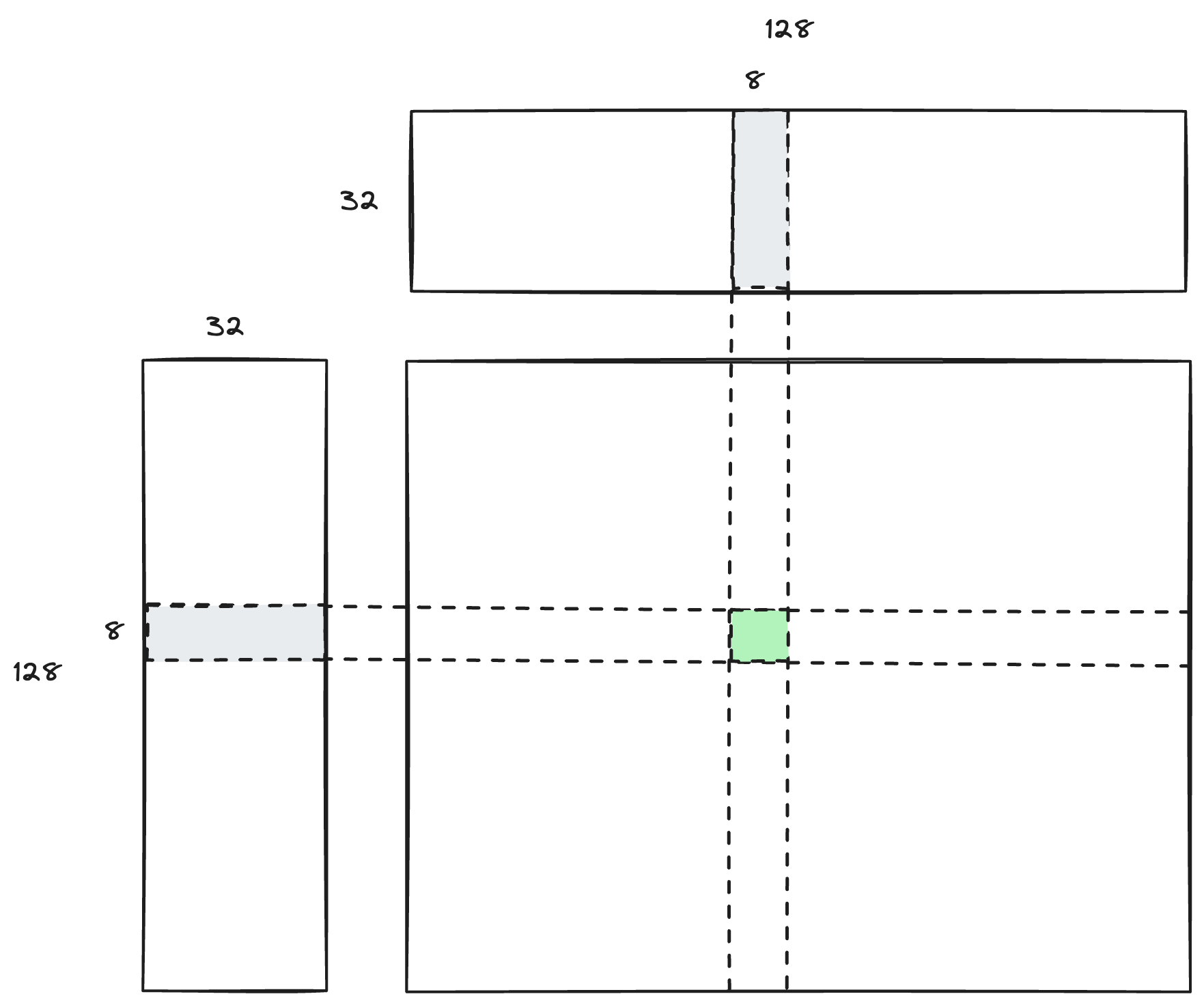
每个 thread 在计算 [8, 32] * [32, 8] 的时候,分成了更小的块去计算,一次计算 [8, 4] * [4, 8] 的矩阵乘法。
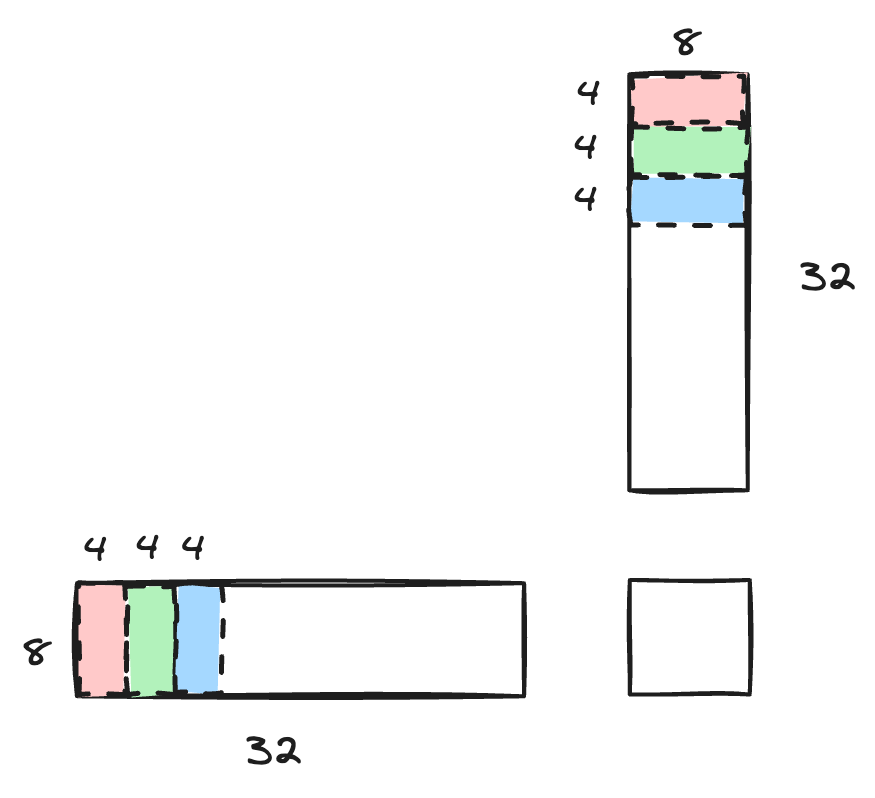
对应如下两个 for loop
for (int si = si_start; si < si_start + 32; si += 4) {
float4 rhs[8];
for (int u = 0; u < 8; ++u) {
rhs[u] = ld_vec(&rhs_s[u + 8 * threadIdx.y][si % 32]);
}
for (int ii = 0; ii < 8; ++ii) {
float4 lhs = ld_vec(&lhs_s[ii + 8 * threadIdx.x][si % 32]);
for (int ji = 0; ji < 8; ++ji) {
vals[ii][ji] += lhs.x * rhs[ji].x;
vals[ii][ji] += lhs.y * rhs[ji].y;
vals[ii][ji] += lhs.z * rhs[ji].z;
vals[ii][ji] += lhs.w * rhs[ji].w;
}
}
}
LayerNorm
__global__ void layernorm_forward_kernel3(float* __restrict__ out, float* __restrict__ mean, float* __restrict__ rstd,
const float* __restrict__ inp, const float* __restrict__ weight,
const float* __restrict__ bias, int N, int C) {
cg::thread_block block = cg::this_thread_block();
cg::thread_block_tile<32> warp = cg::tiled_partition<32>(block);
int idx = blockIdx.x * warp.meta_group_size() + warp.meta_group_rank();
if(idx >= N) {
return;
}
// the row of input that this group of threads is responsible for
const float* x = inp + idx * C;
// mean
float sum = 0.0f;
for (int i = warp.thread_rank(); i < C; i += warp.size()) {
sum += x[i];
}
sum = cg::reduce(warp, sum, cg::plus<float>{});
float m = sum / C;
if(warp.thread_rank() == 0 && mean != nullptr) {
__stcs(mean + idx, m);
}
// rstd
sum = 0.0f;
for (int i = warp.thread_rank(); i < C; i += warp.size()) {
float diff = x[i] - m;
sum += diff * diff;
}
sum = cg::reduce(warp, sum, cg::plus<float>{});
float s = rsqrtf(sum / C + 1e-5f);
if(warp.thread_rank() == 0 && rstd != nullptr) {
__stcs(rstd + idx, s);
}
// final normalization and scaling by weight/bias
float* o = out + idx * C;
for (int c = warp.thread_rank(); c < C; c += warp.size()) {
// load and store using the .cs "streaming" hint to the compiler,
// indicating that this data will not be reused soon, and can be streamed through the caches
// this allows the threads to get more cache-hits for the (shared) weight and bias parameters
float n = s * (__ldcs(x+c) - m);
__stcs(o+c, n * weight[c] + bias[c]);
}
}
void layernorm_forward(float* out, float* mean, float* rstd,
float* inp, float* weight, float* bias,
int B, int T, int C) {
const int block_size = 128;
const int N = B * T;
const int grid_size = CEIL_DIV(N * 32, block_size);
layernorm_forward_kernel3<<<grid_size, block_size>>>(out, mean, rstd, inp, weight, bias, N, C);
cudaCheck(cudaGetLastError());
}
这个 kernel 需要关注的点是对于 cooperative_groups 这个库的运用,比如下面这段代码
cg::thread_block block = cg::this_thread_block();
cg::thread_block_tile<32> warp = cg::tiled_partition<32>(block);
int idx = blockIdx.x * warp.meta_group_size() + warp.meta_group_rank();
if(idx >= N) {
return;
}
这里实现了一个 warp 负责一行的计算,如果用 blockIdx, blockDim, threadIdx 来实现如上的功能,代码差不多像下面这样
int warp_size = 32;
int idx = (blockIdx.x * blockDim.x + threadIdx.x) / warp_size;
if(idx >= N) {
return;
}
而随后 warp.thread_rank() 可以替代 threadIdx.x % warp_size,整体来说感觉使用 cooperative_groups 可以让代码更加清晰,直观。
cooperative_groups 的另一个核心功能是支持更细粒度的 thread group 的 sync,传统使用 __syncthreads() 的时候,整个 block 的所有 thread 都会被阻塞。在我们的这段代码中,cg::thread_block_tile<32> warp = cg::tiled_partition<32>(block) 把 32 个 thread 分成一个 thread group (warp),在 warp level 上进行 sync,sum = cg::reduce(warp, sum, cg::plus<float>{})。
Cooperative Groups: Flexible CUDA Thread Programming 这篇文章对 cooperative_groups 有详细的介绍,强烈推荐阅读。